Shiny Dashboard AWS Deployment
Table of Contents
From Local to Scalable: Iterating on Shiny Dashboard Deployment with AWS
As a data scientist today, it’s no longer enough to just analyze data. Our roles often require us to wear many hats — not just building models, but also deploying, maintaining, and communicating them effectively. This post is about one of those hats: deploying a Shiny-based dashboard to AWS, and how I iterated through multiple versions to arrive at a final architecture that balances usability, scalability, and cost. I’ve been working on a fascinating project over the past three years — it’s finally nearing completion. While I can’t share too many details until the paper is published, I can say this: it’s one of the most exciting datasets I’ve worked with, and we’ve uncovered a lot from it. But a great project shouldn’t end with just a paper. We wanted to make the results accessible and interactive for other researchers, and sharing data is not only valuable for transparency and collaboration — it’s also increasingly required by journals and funders. So, I decided to go a step further and create a data dashboard to present everything in a user-friendly way. Since most of the analysis was done in R, it made sense to build the dashboard using Shiny. In this post, I’ll focus on the deployment design process — the architecture, decisions, and lessons learned. I’ll skip the Shiny app development part for now (maybe a future post!) and assume we already have a working Shiny dashboard.
Version 1: Docker on EC2
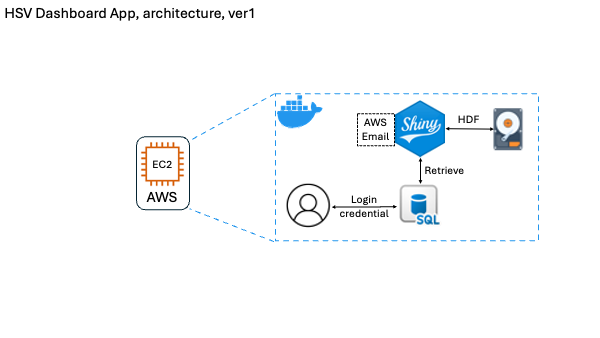
In the initial design, I wrapped the entire app — including the R code, UI, data, and even a local SQL database — into a Docker image, and deployed it on an AWS EC2 instance. I also implemented a basic user login feature. The login information (email, password, etc.) was saved locally in the container using a built-in SQL database, and I used AWS’s email service to handle account verification.
Pros:
• Simple to deploy
• Everything bundled in one image
• Worked well for development and internal review
Cons:
• No autoscaling: all app data lived inside the container, so every new EC2 instance created during scaling duplicated the entire dataset.
• SQL data wasn’t shared: if a user registered on one instance and was later routed to another (via load balancer), their account didn’t exist — which broke login and user tracking.
• Poor separation of concerns: app logic, data storage, and user management were all bundled together.
Version 2: Modular AWS Architecture
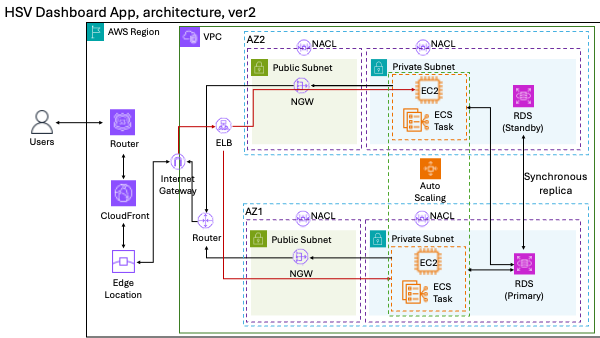
To solve these issues, I redesigned the architecture to decouple services and take full advantage of AWS components. Here’s what changed:
• App: Still containerized with Docker, but now hosted using AWS ECS (Elastic Container Service), which was deployed on EC2 instances.
• Storage: Large data files were stored in S3 instead of inside the Docker image.
• Database: Moved the user authentication info to AWS RDS (a managed SQL service), so it was shared across all containers.
• Email: Switched to AWS SES for account verification.
• Authentication: Considered using AWS Cognito for user management.
• Scalability: Enabled autoscaling on ECS and added a load balancer to handle high traffic.
This version was much cleaner and production-ready. But it still had trade-offs, including increased cost and complexity, especially since the login system added overhead without delivering much value.
Final Version: Simpler, Cheaper, and Scalable
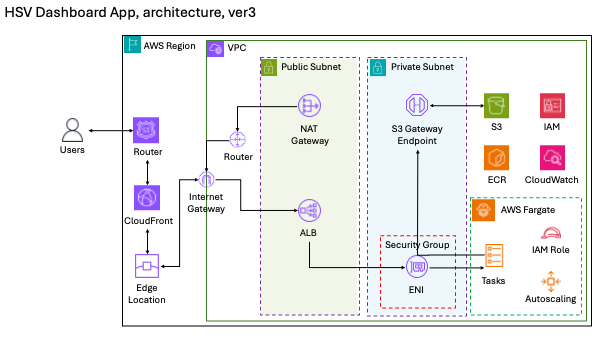
In the final version, I made a big decision: remove the login system entirely. It was mainly used for tracking user access history, which wasn’t essential. By removing it:
• I no longer needed RDS for user data.
• No email verification, so I dropped SES.
• No need to store user login history in S3.
• Significant cost and maintenance savings.
With those simplifications, I was able to deploy the app using AWS Fargate, which allowed me to run containers without managing EC2 instances. This made the system more scalable, resilient, and cost-effective, while still delivering a great experience for users.
Closing Thoughts This deployment journey taught me a lot about AWS services and architectural trade-offs. I started with a simple one-box setup, moved to a modular design, and then simplified again — each version reflecting what I learned along the way. One big takeaway: every step of a project should involve thinking ahead, because early decisions can heavily influence what’s possible down the road. For example, in our case, we completed most of the data analysis before even considering building a dashboard. At the time, we didn’t pay much attention to how the data was stored. Later, when deploying to AWS, we realized that Python tools offer far better support for accessing HDF5 files in the cloud than R does — a consideration we hadn’t planned for early on. These kinds of realizations highlight that a dashboard like this isn’t just a visual layer — it’s the tip of a much larger, interconnected system. From how you clean and store data to how you deliver it to end users, each layer affects the next. Experience definitely helps, but so does taking a more systemic approach from the start. I hope this post helps others learn from my process. Once the paper is published, I’ll share the dashboard link here. Until then, feel free to reach out if you’re on a similar journey — I’d be happy to talk.